科研专栏
研究方法
研究问答
研究进展
科研服务
数据库搭建(EDC)
统计分析服务
医咖社区
DRPP工作台
会员
提问
登录
/
注册
内容领域
:
全部
软件操作
研究设计
样本量估算
统计分析
论文撰写
数据管理
文献检索管理
基金申请
循证医学
全部
SPSS
R
Stata
SAS
PASS
Medcalc
EndNote
NoteExpress
全部
研究设计思路
随机对照试验
队列研究
病例对照研究
横断面研究
诊断试验
真实世界研究
全部
样本量估算要点
随机对照试验/队列研究
病例对照研究
横断面研究
诊断试验
非劣效性试验
生存分析
全部
统计描述
假设检验
数据整理
统计操作指导
统计作图
统计分析思路
Meta分析
预测模型
全部
论文报告规范
观察性研究报告规范
论文撰写指导
全部
数据管理SOP
数据管理软件
电子数据采集系统(EDC)
全部
PubMed检索
万方数据检索
CNKI检索
EndNote管理文献
NoteExpress管理文献
全部
基金申请来源
基金标书撰写
全部
临床指南
课程类别
:
全部
基础课
高级课
公开课
专题合集
FDA推荐:连续变量的一致性评价『ATE/LER区域法』
其主要原理是分析一种仪器(或方法)的测量结果与另一种仪器(或方法)测量结果的总体吻合度,并用图形直观地反映这一结果,最后结合临床意义,得出两种测量仪器(或方法)是否具有良好的一致性。
发表于2018-09-07
在处理缺失值前,你得先搞清楚是哪种缺失
缺失值主要可分为三种情形:完全随机缺失、随机缺失、非随机缺失
发表于2018-09-05
连续变量的一致性评价,教你一种图示法『Bland-Altman法』
无序分类变量,一般采用Kappa一致性检验;有序分类变量(等级变量),采用加权Kappa或Kendall系数评价一致性;连续变量的一致性评价,除了之前提到的组内相关系数(ICC),还有另外两种图示方法——Bland-Altman法和ATE/
发表于2018-09-03
匆匆地,你得到了操作和结果,却错过了算法和思路
我发现很多人在统计学应用中,往往只关心软件操作,而不想去了解方法背后的思路和具体算法。甚至就希望:你就把程序发给我就行了,我把数据套上,得出结果就可以了。
发表于2018-09-01
为了发论文而“美化”数据,你身边有人这样做吗?
和你同在一个课题组的小 A ,实验做了快一个学期了,得到的数据却不怎么漂亮。为了一个辛苦了好几个月但迟迟看不到希望的研究,TA 稍微调整了一下初始条件来“创造”一个更符合预期的数据,或者舍掉了那些偏差较大的数据。
发表于2018-08-31
说到控制混杂因素,怎么能不提多因素分析!
分层分析仅仅适用于混杂因素较少,且多为分类变量的情况。当我们的研究中存在较多的混杂因素,且混杂因素较为复杂(例如混杂因素为多分类变量或连续变量)时,应该如何对混杂因素进行控制和调整呢?
发表于2018-08-16
试验过程中主要终点还能调整吗?来看研究实例!
适应性设计中,可以在保证试验统计学严谨性以及试验整体性的前提下,根据不断积累的信息或试验外部信息调整主要终点,降低试验的风险,优化试验的产出。常见该类设计类型是由非劣效终点改变为优效性终点。
发表于2018-03-05
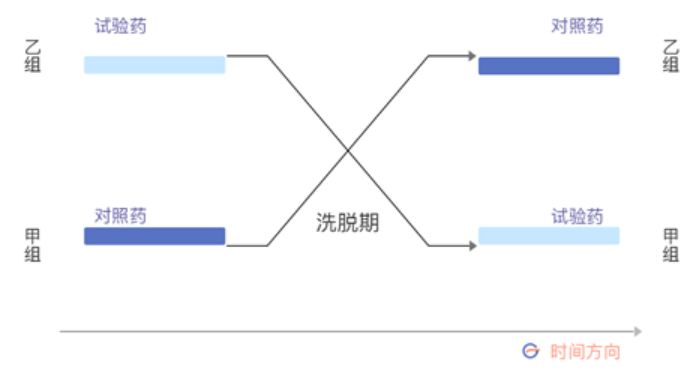
想应用交叉设计?你得先注意4个问题
研究对象被随机分为甲、乙两组。甲组先用试验药物,乙组先用对照药物。一个疗程结束后,间隔一段时间(目的是消除治疗药物的滞留影响),然后甲组用对照药物,乙组用试验药物,最后分析比较疗效和安全性。
发表于2018-03-01
样本量重估计设计——试验过程中重新调整样本量,来看一项研究实例
样本量重估计设计其实可以很简单地解决样本量估计的问题。如果采用该设计,可以先设定初始的样本量,然后在试验过程中通过累积的数据对样本量进行重新估计,重新调整,这样一来便可大大降低试验的不确定性。
发表于2018-02-28
临床试验中,为何会设置安慰剂导入期?
在RCT中,部分研究对象可能不耐受试验干预措施,导致不依从或失访。如果大量研究对象在随机分组后不依从或失访,其数据将会缺失,从而给统计分析造成困难,试验结论的可靠性也将受到影响。
发表于2018-02-25
推荐课程
文献计量分析学习目的
文献计量分析图谱基础
论文中如何写好研究的局限性?来看示例
医学公开数据研究现状
上一页
1
...
7
8
9
10
11
12
下一页
公众号
统计咨询
扫一扫添加小咖个人微信,立即咨询统计分析服务!
会员服务
SCI-AI工具
积分商城
意见反馈