

2021年4月15日,国家药品监督管理局药品审评中心官网发布了《用于产生真实世界证据的真实世界数据指导原则(试行)》。
链接:
http://www.cde.org.cn/news.do?method=viewInfoCommon&id=eaed86b800e8d9d9
该指导原则从真实世界数据的定义、来源、评价、治理、标准、安全合规、质量保障、适用性等方面,对真实世界数据给出具体要求和指导性建议,以帮助申办者更好地进行数据治理,评估真实世界数据的适用性,为产生有效的真实世界证据做好充分准备。
以下摘录《指导原则》中关于“真实世界数据治理”的内容:
数据治理是指针对特定临床研究问题,为达到适用于统计分析而对原始数据所进行的治理,其内容包括但不限于:
数据安全性处理、数据提取(含多个数据源)、数据清洗(逻辑核查及异常数据处理、数据缺失处理)、数据转化( 数据标准、通用数据模型、归一化、自然语言处理、医学编码、衍生变量计算)、数据传输和存储、数据质量控制等若干环节。
(一) 个人信息保护和数据安全性处理
真实世界研究涉及个人信息保护应遵循国家信息安全技术规范、医疗大数据安全管理相关规定,对个人敏感信息应进行去标识化处理,确保根据数据无法进行个人敏感信息匹配还原,通过技术和管理方面的措施,防止个人信息的泄漏、损毁、丢失、篡改。
数据安全性处理应基于研究所涉及的各种数据的类型、数量、性质和内容,尤其对于个人敏感信息,建立数据治理各环节的数据加密技术要求、风险评估和应急处置操作规程,并开展安全措施有效性审计。
(二) 数据提取
根据源数据的存储格式、是否为电子数据、是否包含非结构化数据等因素选择合适的方式进行数据提取,在数据提取时均应遵守以下原则:
数据提取的方法应通过验证,以保障提取到的数据符合研究方案的要求。数据提取应确保提取到的原始数据与源数据的一致性,应对提取到的原始数据与源数据进行时间戳管理。
使用与源数据系统可互操作或集成的数据提取工具可以减少数据转录中的错误,从而提高数据准确性以及临床研究中数据采集的质量和效率。
(三) 数据清洗
数据清洗是指对提取的原始数据进行重复或冗余数据的去除、变量值逻辑核查和异常值的处理以及数据缺失的处理。需要注意,在修正数据时如果无法追溯到主要研究者或源数据负责方签字确认,数据不应做修改,以保证数据的真实性。
首先在保证数据完整性的前提下去除重复数据及不相关数据。在不同数据源合并过程中,可能产生重复数据,需要去除。同时由于数据源与通用数据模型映射关系的不准确,可能会采集到与研究目标不相关的数据,从数据集中删除不需要的观测值可以减少不必要的工作。
然后进行逻辑核查和异常数据处理。通过逻辑核查可以发现原始数据或者提取数据时产生的错误,例如出院时间早于入院时间,出生年月按年龄推算不符,实验室检查结果不符合实际,定性判断结果与方案中定义的判断标准不一致等。对异常数据的处理要非常谨慎,避免由此产生的偏倚。对于发现的错误和异常数据应通过进一步核实才能更改数据,数据的更改应保留记录。
最后在统计分析时对数据缺失进行处理,对于不同研究,数据的缺失程度、缺失原因和变量值的缺失机制不尽相同。如果涉及缺失数据的填补问题,应根据缺失机制的合理假设采用恰当的填补方法。
(四) 数据转化
数据转化是将经过数据清洗后原始数据的数据格式标准、医学术语、编码标准、衍生变量计算,按照分析数据库中对应标准进行统一转化为适用真实世界数据的过程。对于自由文本数据的转化可使用可靠的自然语言处理算法,在保障数据转化准确、可溯源的前提下,提高转化效率。
在进行衍生变量计算时,应明确用于计算的原始数据变量及变量值、计算方法及衍生变量的定义,并进行时间戳管理,以保障数据的准确性和可追溯性。
(五) 数据传输和存储
真实世界数据的传输和存储应当基于可信的网络安全环境,在数据收集、处理、分析至销毁的全生命周期予以控制。在数据传输和存储过程中都应有加密保护。此外,应建立操作设置审批流程、角色权限控制和最小授权的访问控制策略,鼓励建立自动化审计系统,监测记录数据的处理和访问活动。
(六) 数据质量控制
数据质量控制是确保研究数据完整性、准确性和透明性的关键。数据质量控制需要建立完善的真实世界数据质量管理体系和标准操作规程,建议原则包括:
1. 确保源数据的准确性和真实性
如电子病历作为关键数据源,应有病历质控标准以满足分析要求。来源于门诊的疾病描述、诊断及其用药信息需要有相关证据链佐证。对于录入过程中的任何修改,需要有负责人的确认和签名,并提供修改原因,确保留下完整的稽查轨迹。
2. 在数据提取时充分考虑数据完整性问题
评估和确立提取字段,制定相应的核查规则和数据库架构。
3. 制定完善的数据质量管理计划
制定系统质控和人工质控计划,确保数据的准确性和完整性。对于关键变量应进行全面的核查和源文件调阅;其它变量可根据实际情况抽样核查,例如,对于人口学信息、数值型变量阈值、编码映射关系等,可按一定比例抽样,核查其准确性与合理性。
(七) 通用数据模型
通用数据模型是多学科合作模式下对多源异构数据进行快速集中和标准化处理的数据模型,其主要功能是将不同标准的源数据转换为统一的结构、格式和术语,以便跨数据库/数据集进行数据整合。
由于多源数据的结构和类型的复杂性、样本规模和标准的差异性,在将源数据转换为通用数据模型的整体过程中,需要对源数据进行提取、转换、加载,应确保源数据在语法和语义上与目标分析数据库的结构和术语一致,见图 2。
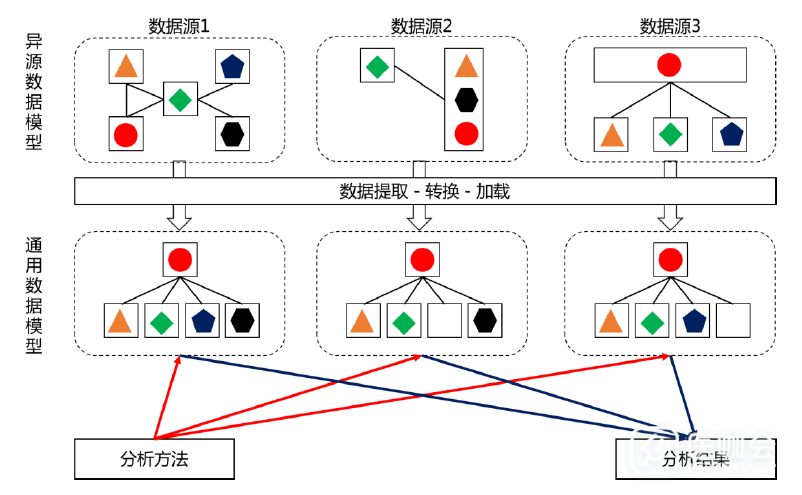
图2. 异源数据模型向通用数据模型转化的示意图
理想的通用数据模型应遵循以下原则:
1. 通用数据模型可以定义为一种数据治理机制,通过该机制可以将源数据标准化为通用结构、格式和术语,从而允许跨多个数据库/数据集进行数据整合。通用数据模型具有访问源数据的能力,是可动态扩展和持续改进的数据模型,并有版本控制;
2. 通用数据模型中变量的定义、测量、合并、记录及其相应的验证应保持透明,多个数据库的数据转换应有清晰一致的规则;
3. 安全性和有效性相关的常用变量或概念都应映射到通用数据模型,以适用于不同临床研究问题,并可通过公认或已知的研究结果进行比对。
(八) 真实世界数据治理计划书
真实世界数据治理计划书应事先制定,与整个项目研究计划同步。如果治理计划书在研究进行过程中需要修订,应与审评机构沟通,同时递交更新后的治理计划书。计划书中应说明使用真实世界数据用于监管决策的目的、 使用真实世界数据的研究设计还应对真实世界数据源数据进行说明。
包括但不限于:
真实世界数据源数据/源文件的类型,例如卫生信息系统数据、疾病登记研究数据、医保数据等;
真实世界数据的源数据/源文件,适当评价其既往应用情况,说明采用的理由;
真实世界数据的治理,即由真实世界数据数据来源到分析数据库的治理过程;
采用的数据模型和数据标准;
缺失数据的处理方法;
减少或控制使用真实世界数据带来的潜在偏倚所采取的措施;
质量控制和质量保证;
真实世界数据的适用性评估。
完整内容请查看全文:
http://www.cde.org.cn/news.do?method=viewInfoCommon&id=eaed86b800e8d9d9

扫码关注“医咖会”公众号,及时获取最新统计教程












确认删除