



最开始学病例对照研究的时候可能有一个疑问,就是为什么只能用比值比(OR),而不能用风险比(RR),按道理直接算也是可以算出RR的。一般的解释是:在病例对照中,我们无法算出总体数量,也就是算risk时,没有固定的分母,或者分母是任意的。而这个分母取决于我们病例匹配的比例,比如当1:1匹配时,RR相对小,当1:100时,RR就会变大。
下面我们来通过一个例子说明。(为了方便,取课本上的例子说明)

如图所示,一个假想的病例对照研究,其中假设我们对总体的发病情况已知:即图右侧的2×2表格,其中A、B、C、D分别代表相对应的个体数量。在病例对照的样本中(图左侧表格),我们假设从总体患病个体中随机抽取f1比例的样本,从总体非患病个体中随机抽取f2比例的样本,为了方便,我们同时假设不存在抽样误差。因此,样本中的个体可以表示为a=f1A,c=f1C,b=f2B,d=f2D。则我们可以计算RR的估计值为:

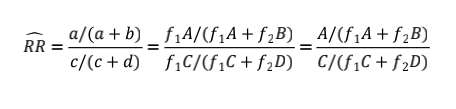

那么既然RR不行,我们再来看看OR为什么可以。
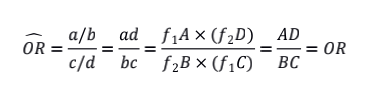


如因果图所示,A代表某种干预,Y代表结果或某种疾病风险,C代表某个个体是否被选择进入病例对照研究样本中(1:不选择,0:选择)。可以想象,因为病例选择是任意的、人为的,所以病例会更多的或更少的选择进入样本中,表示为Y对C的因果效应。而当干预A对选择人群中存在其他某种疾病风险的关联时,例如对某个疾病有保护作用,则当选择对照样本时,更容易选择有这个疾病的人群,表示为A对C的因果效应(或间接因果效应A-M-C)。
因此,当我们选取C=0的样本时,相当于校正了C变量,而C变量同时被A和Y影响着,属于碰撞变量(collider),因此,引入选择偏倚,也称为不适当对照选取偏倚。












确认删除