





作者:李侗桐;审稿:张耀文
相关性分析主要用于:(1)判断两个或多个变量之间的统计学关联;(2)如果存在关联,进一步分析关联强度和方向。
那么,什么样的研究可以进行相关性分析呢?我们在这里列举了几个相关性研究的例子供大家参考:

确定要进行相关性分析后,对两个变量或多个变量进行相关性分析所采取的统计方法是不同的。那么,怎么判断研究变量的数量呢?
我们分别就两个变量的研究和三个及以上变量的研究进行了举例,帮助大家理解。同时,我们也对例子中变量数据类型进行了描述(如,连续变量、二分类变量、无序分类变量和有序分类变量)。
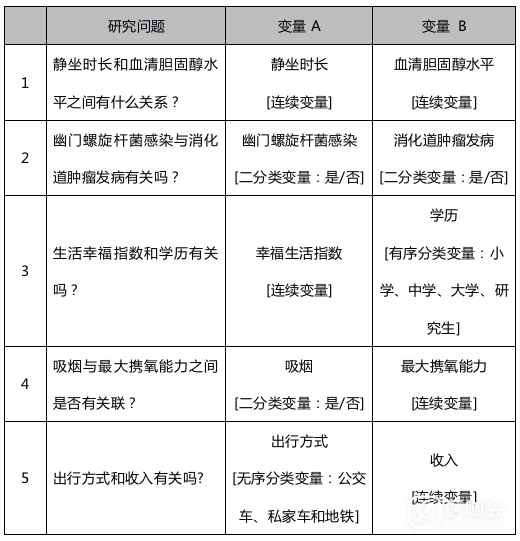

确定拟分析变量之间的相关性后,我们需要判断变量的数据类型。
变量的数据类型主要分为连续变量、二分类变量、无序分类变量和有序分类变量4类。拟分析的变量可以同属于一个数据类型,也可以分属不同的数据类型。根据这两个变量数据类型的不同,应采用的统计分析方法也不同。
连续变量是指对连续的指标测量所得到的数值,比如体重。其特点是等距区间的差异相同,例如体重在50kg-60kg之间的差异与60kg-70kg之间的差异相同。连续变量的示例如下:
a.距离(以米为单位)
b.温度(以摄氏度为单位)
c.时间(以小时为单位)
d.体重(以千克为单位)
e.成绩(以0-100分为计算区间)
有序分类变量可以有两个或者多个已排序的类别。举例来说,如果某患者的治疗结果是“痊愈”、“好转”、“不变”或者“恶化”。这就是一个有序分类变量,因为可以对四个类别进行排序。
需要注意的是,虽然我们可以对有序分类变量的类别排序,但还需要判断这种类别排序是不是等距的。例如,用各年龄段的近似中位数代表年龄类别,即24(18-30)岁、40(31-50)岁、60(51-70)岁、80(70岁以上)岁,可以将年龄视为定距变量。












确认删除