

来源:“小白学统计”微信公众号;作者:冯国双。
很多人在做多因素分析的时候,往往都按这种方式:首先把所有因素挨个做个单因素分析,然后单因素分析有意义的变量,再放到多因素分析中,最后得到一个多因素分析模型。然后完事,发表文章。当然,在单因素分析的那一步,有的人用0.05作为水准,P小于0.05的变量纳入多因素;有的则以0.1或0.15、0.2等为水准,P小于0.1或0.15、0.2的变量才纳入多因素分析。
无数人都曾问过我这个问题:我先做单因素分析,再做多因素分析,这种做法对吗?或者说:别人发表的文章,全都是这么做的,所以我也这么做。
那么,这种方式到底对不对?我们今天就来讨论一下。
首先,公布答案:没有所谓对不对。也可以说对,也可以说不对。注意这里我不是打禅机,也不是卖关子,而是确实如此。其实,严谨的说法就是:具体问题具体分析,有时这么做没问题,有时会有问题。但有一点是很明确的:决不能死板地完全按这一规则来分析。
可能你现在还不是很明白,我们通过一个例子来说明。
有1个因变量y,4个自变量a、b、c、lx,假定我们更关注lx这个变量,但其他变量也关心(我想临床医生应该明白我在说什么。很多情况下,临床医生虽然说是筛选危险因素,其实心里还是有倾向性的,更希望自己心目中的变量有意义)。先看单因素分析结果如下:
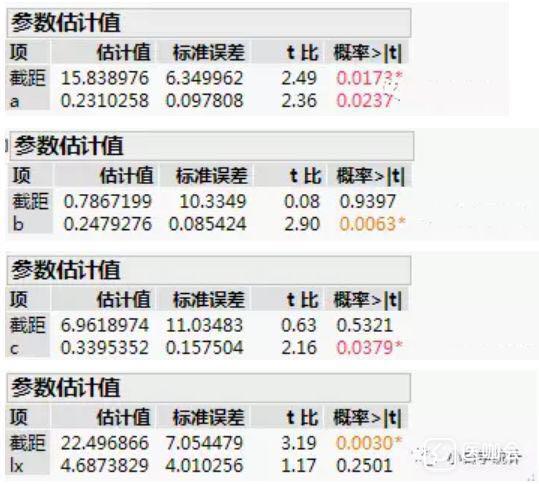
看到这里,估计有的人心里就得咯噔一下,心里最希望的变量lx,偏偏没有统计学意义。如果按常规的思路,单因素分析的P值这么大,无论如何也入选不了多因素分析。通常我们会在单因素分析中把检验水准稍微设的宽松一些,但除非这里设到0.3,否则即使在0.25的检验水准上,依然无统计学意义。
那是不是说,我们后面就把a、b、c三个变量纳入多因素分析,不管lx这个变量了呢?













确认删除