





Stuart J. Pocock在Journal of the American College of Cardiology上发表了系列文章,介绍临床试验报告的一些统计学考虑[1]。上一期我们聊到无论是主要终点(复合终点),还是次要终点的解读都需要谨慎,避免以偏概全。本期旧话重提,重新审视一下临床研究常用到的一些统计学方法。
协变量调整
观察性研究(比如,病例对照研究和队列研究)经常要考虑到因组间因素不均衡可能造成的混杂。为了减少混杂因素对于研究结果的影响,可针对混杂因素进行匹配、分层分析或协变量调整等(最近推送了多篇介绍混杂因素调整的文章,还没看的小伙伴赶快查看历史消息)。但是,随机对照研究还需要考虑协变量的调整吗?几个实例告诉你答案~
1. RCT应该像观察性研究一样调整基线变量吗?
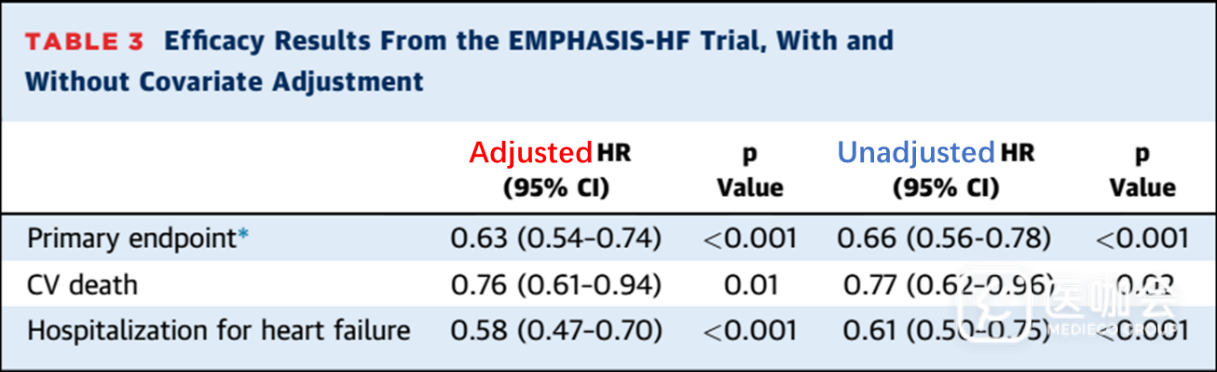
EMPHASIS-HF研究[2]评价了依普利酮治疗慢性心衰患者的获益情况,共纳入2737名患者,平均随访21个月。在评价组间疗效时,研究者应用Cox等比例风险模型,调整了包含年龄在内的13个基线变量。如表1所示,3个结局指标调整后的HR比未调整的HR小(远离“1”)。
表1. EMPHASIS-HF研究
与定量结局(方差分析或协方差分析)相似,对于二分类(Logistic回归)或时间-事件类结局(Cox等比例风险模型)在调整基线数据时,并不会显著提高效应值(OR/RR/HR)的估计精确度(置信区间仅仅变小了一点);一定程度上,相应的点估计值会倾向于远离零假设,即组间疗效有差异。
例如,CHARM研究[3]评价坎地沙坦对慢性心衰患者的获益情况,共纳入7599名患者。研究发现,和安慰剂组相比,心衰患者在常规治疗的基础上加用坎地沙坦治疗随访3.2年后,未调整基线的全因死亡风险并没有显著降低(HR=0.90, 95%CI: 0.83-1.00, P=0.055)。












确认删除