



一、倾向评分的提出背景
观察性研究中,以队列研究为例,暴露因素的分配(如是否吸烟)通常不受人为控制,暴露组和非暴露组的形成无法等同于随机分组,因此很难做到研究对象在组间均衡可比。
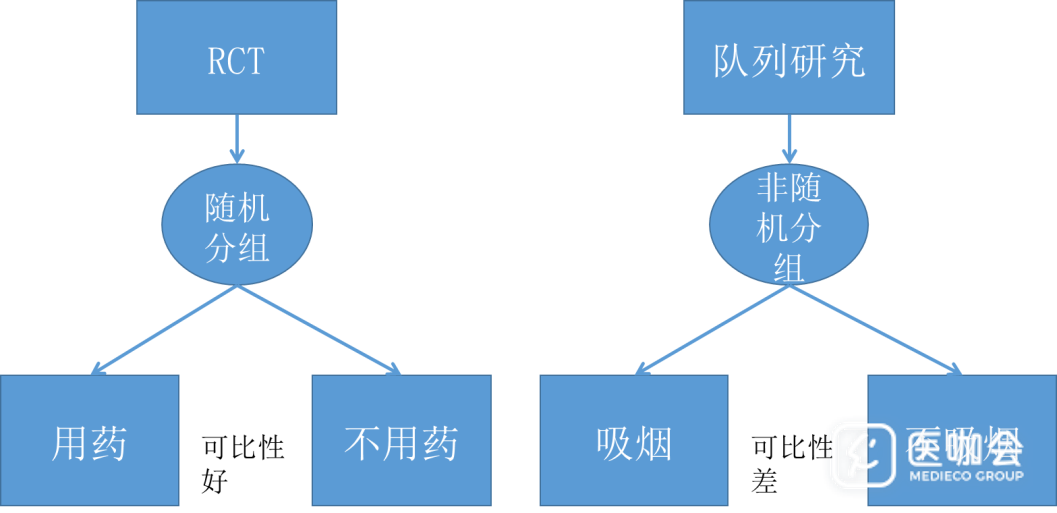
组间因素不均衡可能造成混杂。调整混杂因素,可针对混杂因素进行匹配、分层分析或协变量调整等。但这些方法控制的混杂因素都不能太多。
当混杂因素较多时可采用倾向评分法(Propensity Score Method)。
二、倾向评分的原理
以吸烟-肺癌的队列研究为例,自然状态下个体是否吸烟与很多因素有关,并不是随机的,吸烟组和非吸烟组会有多个基线特征不平衡。
那么,倾向评分如何解决这个问题呢?
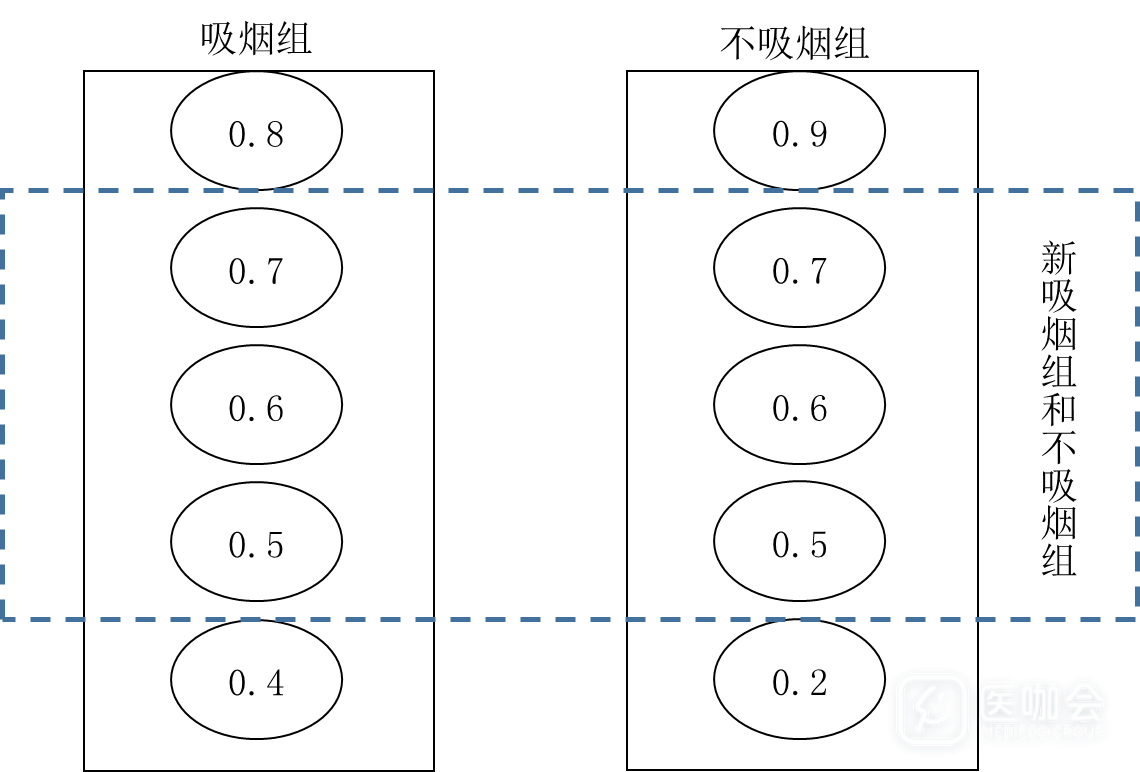
图中椭圆代表个体,数字代表成为吸烟者的概率
如图,计算研究对象在多种背景因素(如年龄、性别等与是否吸烟有关的因素)下成为吸烟者的概率(即倾向评分),匹配概率相等或相近的个体,组成新的吸烟组和不吸烟组,此两组可近似为随机分组,组间相关因素可达到均衡。
由此,组间分配不均衡的多个变量,被“倾向评分”一个综合指标所代替,达到了“降维”的效果。除采用匹配法外也可把倾向评分作为协变量进行调整。
三、倾向评分的应用
倾向评分控制混杂的方法主要有倾向评分匹配、分层、回归调整和加权标化。
倾向评分匹配,就是依据倾向评分大小进行配对。以下介绍最常用的倾向评分最近法:
倾向评分最近法(nearest available matching on the estimated propensity score):先规定一个界限(文献里称为Caliper),如<0.05,然后在另一组寻找与要匹配的个体倾向评分值差异<0.05的个体,例如队列研究中暴露组某个体倾向评分值为0.50,则在非暴露组寻找倾向评分值在0.45-0.55范围内的个体,匹配个体可有多个。一旦配对成功,匹配的个体将被排除。在吡格列酮和膀胱癌的队列研究中,研究者生成了两个队列,一个是1:1匹配的队列,一个是1:n(n最大为10)匹配的队列,其生成过程采用的便是此方法。












确认删除