

内容来自:“小白学统计”微信公众号,感谢作者授权
样本量估算是一个老生常谈的话题,也是让不少临床医生头疼的话题。很多情况下,可能统计学家都会奇怪:样本量估算是挺简单的,照着公式代入相应的参数就行了,为什么好多人还是不大清楚呢?
我也考虑过这个问题,后来我想,可能最主要的问题不在于样本量估算本身是不是简单,而是与样本量估算的一系列问题。如果只说样本量估算公式本身,确实非常简单,就算没有统计软件,用excel自己算算都很容易,更不用提有这么多的便捷的统计软件了。那为什么临床医生还是每次碰到样本量问题就要去咨询统计学家呢?
我仔细琢磨了一下这个问题,决定还是再写一篇关于这个老生常谈的话题。本文所介绍的样本量估算,先只涉及组间比较的情况,这也是临床研究中最常见的情形。几乎所有统计软件都能实现组间比较的样本量估算。
我想,对于临床医生来说,大家并不是觉得样本量估算公式很麻烦,也不是不会使用统计软件,事实上,很多统计软件都无需编程,就是简单在界面中输入两三个参数值,就出来结果了。然而最大的问题不在于输入这几个数值,而是临床医生不知道这几个数值到底是什么,代表什么意思,为什么要输入这些,等等。
先说一些样本量估算前的专业设定:
第一,要先确定你的主要评价指标是什么(这是临床专业问题,如果你连这个都确定不了,那也不用做研究了),样本量是基于主要评价指标估算出来的。经常看到有的标书中写的主要评价指标是有效率,而前面的样本量估算却写着“根据两组VAS评分,计算……”。样本量估算所用到的指标,要跟你的主要评价指标一致。
第二,要确定你的主要评价指标有几个。这一点已经被强调过无数次:主要评价指标最好就是1个,不要那么多。但是,很多临床医师依然始终不愿意接受这一观点,最主要的问题就是觉得做一次研究不容易,收一次患者不容易,一定要多设置几个指标。然而,科研不会考虑你收研究对象容不容易,甚至说,评审人也不会考虑你这种现实问题,更重要的是考虑科学性。
如果从临床角度,确实需要设置2个主要评价指标,这种情况下就需要对两个指标分别估算样本量,而且估算时的一类错误需要重新分配(本文后面会有介绍)。但是仍然建议,如无必须,尽量一个主要指标就行。
当你确定了主要指标后,就可以开始估算样本量了。那估算样本量需要考虑哪些因素呢?下面从最实用的角度来说一下。
以专业的样本量估算软件PASS的界面为例(其它软件所需的参数都一样,只是界面不同而已),对于组间比较,需要指定的一共就这么几个参数(这一界面是两组均值比较):alternative hypothesis(备择假设,更明确地说是指定单侧检验还是双侧检验)、power(把握度)、alpha(一类错误)、group allocation(两组例数比)、u1和u2(两组均值)、 σ(合并标准差)。
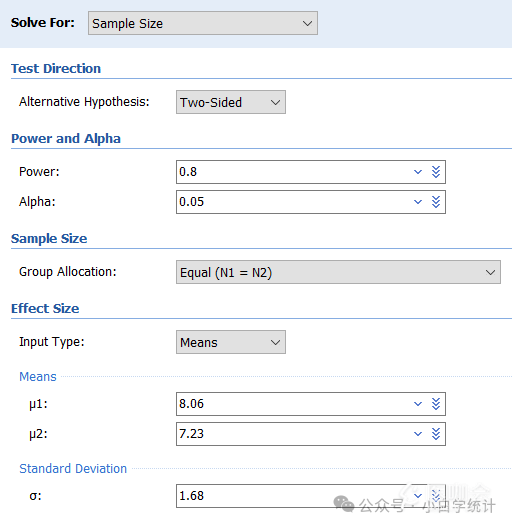
对于临床医师来说,可能有两个问题:第一,不知道该什么设定,如把握度和一类错误;第二,不知道该如何获取,如两组均值和标准差。一旦知道了,直接填上就行了。所以主要就这两个方面说一下。
第一,不知道该如何设定的内容
这部分内容是通用部分,不管是两组比较还是多组比较,不管是比较均值还是率,都需要设定这些。
单双侧、一类错误、把握度、两组例数比,需要自己设定,该如何设定呢?如果你没有任何概念,那就设定一类错误0.05,把握度0.8,这是最常用的设置。
如果你有一定的想法,比如不差钱,不差研究对象,这种情况下,可以设定提高把握度,这样可以有更大的把握能够在最后的统计学检验时出现“有统计学差异”的阳性结果。
如果你前面确定了2个主要评价指标,这时候不仅要对两个指标分别估算,而且还得重新设定一类错误。通常最简单的方式是每个指标分别指定一类错误为0.025(合起来是0.05)。其实样本量估算与后期的统计分析是相呼应的,如果你最后打算比较两个主要指标,那最后统计分析也需要按每个指标0.025来做检验,保证2个指标的一类错误合起来不超过0.05,所以事前的样本量估算也按这个来。
绝大多数情况下,统计学检验采取的都是双侧检验。但是在一些特殊场景下,建议用单侧。比如阳性治疗与安慰剂的对比、A+B与A的对比(例如,中药+西药与单独西药相比),通常这些可以设为单侧。因为如果阳性药连安慰剂都没有把握超过的话,那干脆别生产了。如果在西药的基础上增加中药,还没有把握超过单独西药的话(既增加患者的费用、又多吃了药),那这种研究意义也不大。所以在类似这些情况下,建议用单侧。
至于两组的例数比例,如无特殊情况,尽量按1:1,这是最常见的方式。有时候如果从实际角度觉得某一组的研究对象更难获得,也可以按1:2这些来,根据实际情况而定。但是,同样的例数下,1:1的效率最高。如果按1:2甚至1:3等,要达到同样的检验效果,需要比1:1的总例数多。












确认删除