

想看自己的学术影响力?可以查这些数据库,但问题来了...
说到比较重要的英文文献数据库,大家第一个想起的或许是PubMed,当然还有Web of Science,Scopus等。
霍普金斯大学医学院(左)和哈佛大学医学院(右)图书馆首页的Popular Resources列出了一些常用的英文数据库,包括PubMed, Web of Science等来源 (来源: welch.jhmi.edu, www.countway.harvard.edu,获取日期: 2017/6/29)
现在也有越来越多的研究人员在精心维护着自己的Google Scholar主页。

(来源:google.com)
确实,在评定学术产出的影响力方面,在线的数据库具有越来越大的影响力。然而,你有没有观察过,在不同的数据库中,同一个人的论文数量、文献引用次数、h-index等学术产出指标有些许不同?(h-index同时衡量了论文的篇数和被引用的次数,比单纯的看影响因子更加全面,更加能够体现学术产出的质量。如果对h-index的计算有兴趣,请看本文最后的附录)
以霍普金斯大学公卫学院的Elizabeth Selvin教授为例,其在Google Scholar和Scopus主页上的论文引用数分别为27030和15118,h-index分别为59和52。显然,这名教授好像在Google Scholar上更有学术影响力。

Elizabeth Selvin教授的Google Scholar(左)和Scopus(右)的引用情况、h-index (来源:google.com, scopus.com)
为了解决这个困惑,来自New York University Langone Medical Center的研究团队利用其所有教职员工进行了一个大规模的分析,让大家能够直观地意识到不同数据库的区别。
研究选取了1469名在PubMed, Web of Science, Scopus, Google Scholar至少有1个h-index大于0的科研人员,并记录其学科领域和所属的学院或机构。之后,用Mann–Whitney U秩和检验比较了每位作者的论文数量、引用数量、h-index。结果1. 论文数量方面,Google Scholar > Web of Science > Scopus > PubMed
2. 引用数量差异比较:对于每位作者,Scopus平均比Web of Science引用数多836,h-index高6.4。还有一些有趣的发现,比如,有Ph.D.学位的科研人员比有M.D.s, D.O.s, D.D.S.s或者Dual degree的科研人员有着更显著的h-index差异(图1);
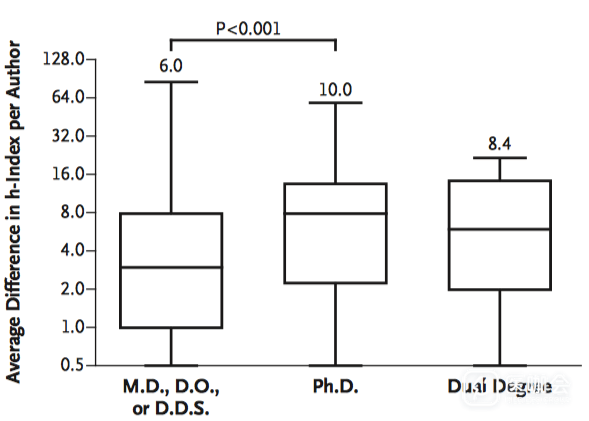
图1. Scopus与Web of Science的h-index的差值的绝对值比较
随着教职的增高,h-index的差异更加显著(图2)。
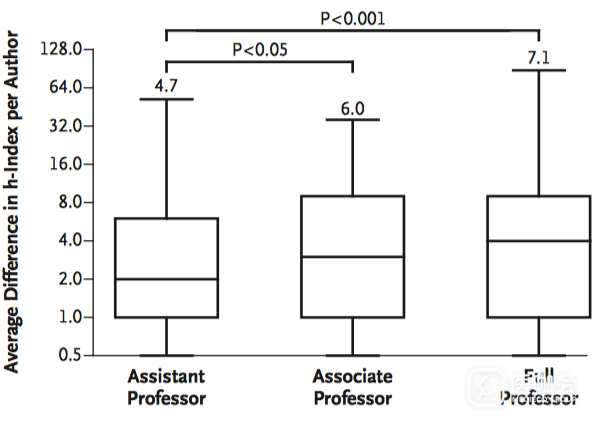
图2. Scopus与Web of Science的h-index的差值的绝对值比较
h-index的差异与被引用次数的差异关联更大,而与论文数量的差异关联较小(图3)。这也意味着h-index更加受到引用数量的影响。若想得到准确的h-index,引用数量需要更加准确。
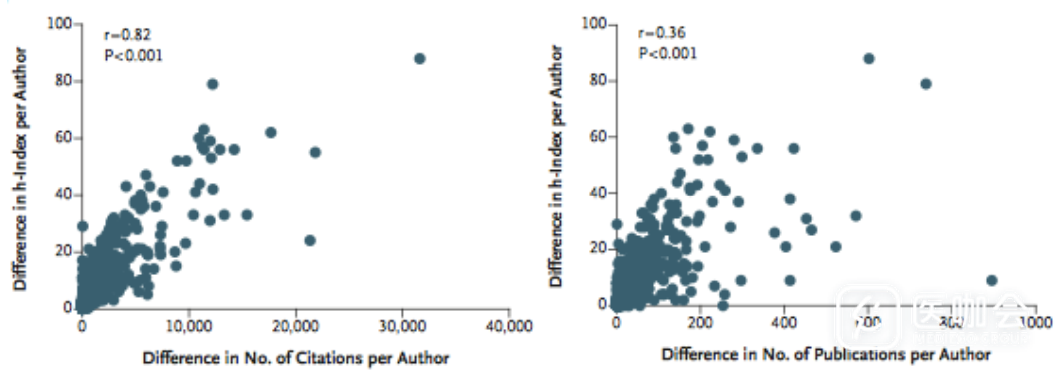
图3. Scopus与Web of Science的h-index差值绝对值和:引用次数差值绝对值(左)/论文数量差值绝对值(右)的关系
然而,为什么不同数据库引用数量会有所不同呢?产生差异的原因主要是数据库所收录的文章数、引用次数不同,同时每个数据库的算法也不尽相同。比如,PubMed一共有近400万条引用,而Google Scholar有约1.6亿条引用,约是PubMed的40倍。
同时,一些不可避免的误差也会导致引用数量的变化,比如杂志名称缩写不同、页码不统一、甚至笔误都有可能导致引用文章不匹配,最终少算了引用数量。尤其对于Scopus这样自动规整作者信息、进行归类的数据库,一个作者很可能拥有多个Profile,导致论文数、引用数降低,h-index因此降低。
那么,你应该怎么办?文章最后的3个建议1. 建立一个Google Scholar的资料页
许多外国大学的学生、教职人员都有属于自己的Google Scholar的学术档案,可以自己完善论文发表情况,并由Google计算相应的指数。同样以Elizabeth Selvin教授为例,这个页面汇集了所有发表的文章及其合作者,以及引用数、h-index等指标,也很容易在Google上搜索到。
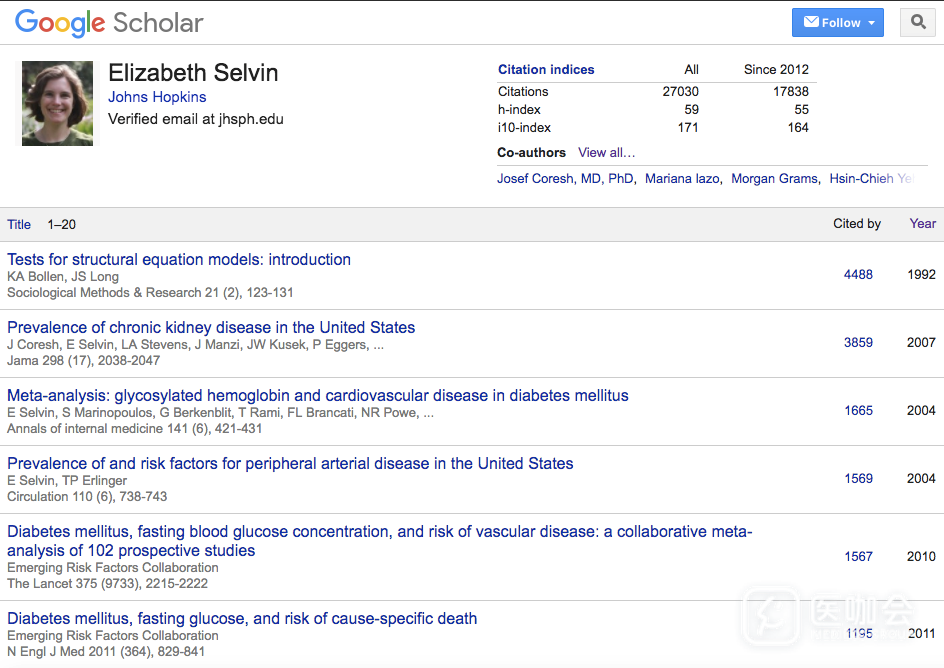
Elizabeth Selvin教授的Google Scholar主页 (来源:Google Scholar, 获取日期: 2017/6/29)

Google Scholar的结果通常在搜索结果的较前面 (来源:Google Scholar, 获取日期: 2017/6/29)
由于众所周知的原因,在中国使用Google Scholar不是很方便,但是仍然有很多中国科研人员通过各种方法建立了自己的页面,非常有利于合作者查看。2017年两会期间,有报道称谷歌学术可能成为第一批返回中国大陆的应用,也让我们拭目以待。

有报道称谷歌学术即将重返中国大陆 (来源:sohu, 获取日期: 2017/6/29)
2. 合并自己在Scopus上隶属于不同机构的的资料页
按照Scopus的说法,其作者标识符功能使用了根据一定标准对作者进行匹配的算法,为同一名作者所著的文献分配一个唯一的编号。因此,有时会可到一个作者有多个条目的情况,尤其是很多时候一个作者可能隶属于不同研究机构。因此尽量将属于自己的资料页进行合并,这样才会有更多的引用数量,提高自己的h-index。
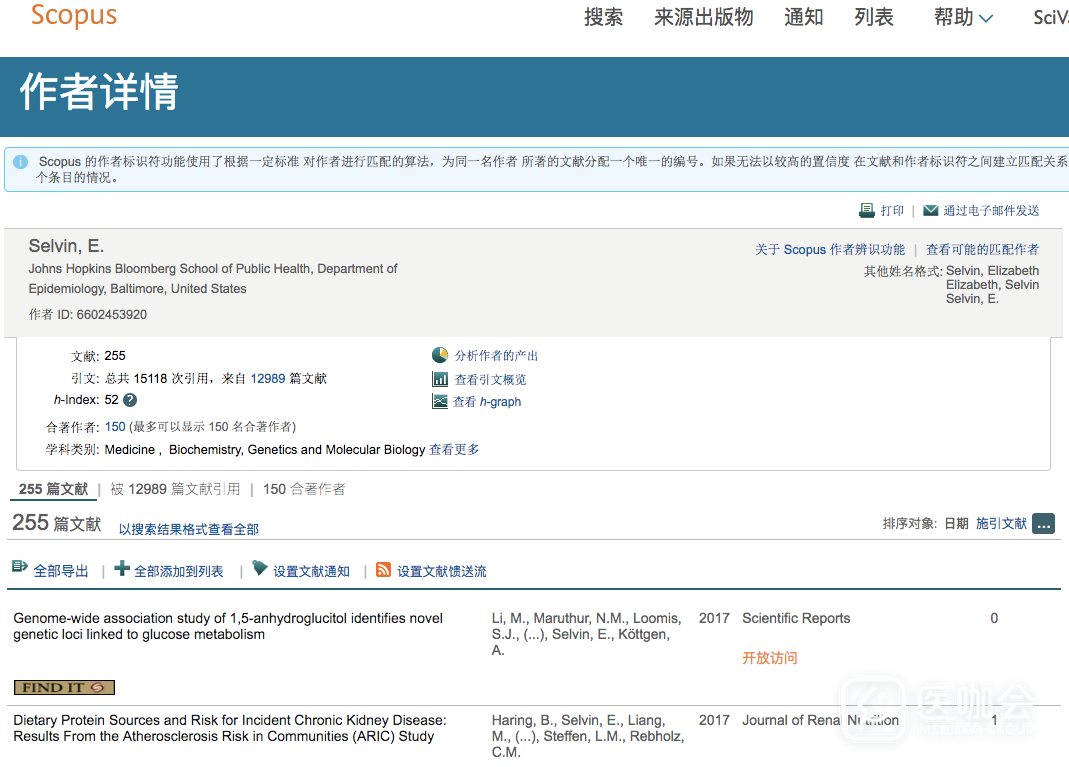
Elizabeth Selvin教授的Scopus主页 (来源:Scopus, 获取日期: 2017/6/29)
3. 注册一个ORCID的ID,合并不同的数据库资料
ORCID的全名是开放的研究员和贡献者ID (Open Researcher and Contributor ID),用以 “方便和唯一地将自己的身份连接到研究对象,如数据集、设备、文章、媒体报导、引文、实验、专利和笔记”(来源: orcid.org),解决作者在科学文献等出版物上人名不唯一而导致难以识别的问题。尤其好的是可以连接包括Scopus在内的众多数据库,更好地把文献作者和其所有的文章联系在一起。现在,也有越来越多的期刊要求使用这个识别码。

ORCID网站(来源:orcid.org)
附录:什么是h-index对于一个人发表的所有文章,有h篇分别被引用了至少h次。
计算方法:将所有已发表文章的引用次数f从高到低排序,然后寻找最后一个引用次数f≥位置序号p的位置
比如: A发表了5篇文章,排序后,被引用次数分别为10 (1),8 (2),5(3),4(4),3(5); B 发表了7篇文章,排序后,被引用次数分别为25 (1),15 (2),8 (3),7 (4),6 (5),3 (6)。 (其中括号中数字为引用次数降序排列后的位置序号,1,2,3,4,5…逐渐增加)
红色的两篇分别为A 和 B最后一个引用次数f≥位置序号p的位置,即A的h指数是4,B 的h指数是5。
现在我们回去看一下定义: - 对于A发表的文章,有至少4篇被分别引用了4次; - 对于B发表的文章,有至少5篇被分别引用了5次。
h指数同时衡量了论文的篇数和被引用的次数,比单纯的看影响因子更加全面,更加能够体现学术产出的质量。比如上面的例子中,就h指数来看,B的学术成就大于A的学术成就。






