





Heart最近发表了一篇综述《Graphics and statistics for cardiology: clinical prediction rules》[1],作者以心血管风险评分(CVD risk factor)为例探讨了如何借助统计图优势构建疾病的预测模型,并提出了6个重要步骤。(表1)
表1. 疾病预测模型的构建

上期我们聊到如何选择合适的统计模型来解释预测变量和结局事件之间的关系,这次我们接着说说模型中变量筛选。
单因素分析结果可靠吗?
相信大多数小伙伴在多因素回归中是这么操作的:先进行单因素分析,单因素分析有统计学意义的变量纳入多因素回归分析中,无意义的变量不纳入分析。但是这样操作是对的吗?显然不是,仅仅将单因素分析有统计学意义的因素纳入多因素回归分析,很可能会将重要的危险因素漏掉。
来看一个栗子,某项研究旨在探索血脂异常的影响因素,单因素分析结果见表2,不同年龄组的血脂异常患病率差异无统计学意义(P=0.072),而血脂异常与性别、饮酒以及BMI均有统计学意义(P<0.01)。
表2. 血脂异常危险因素的单因素分析结果
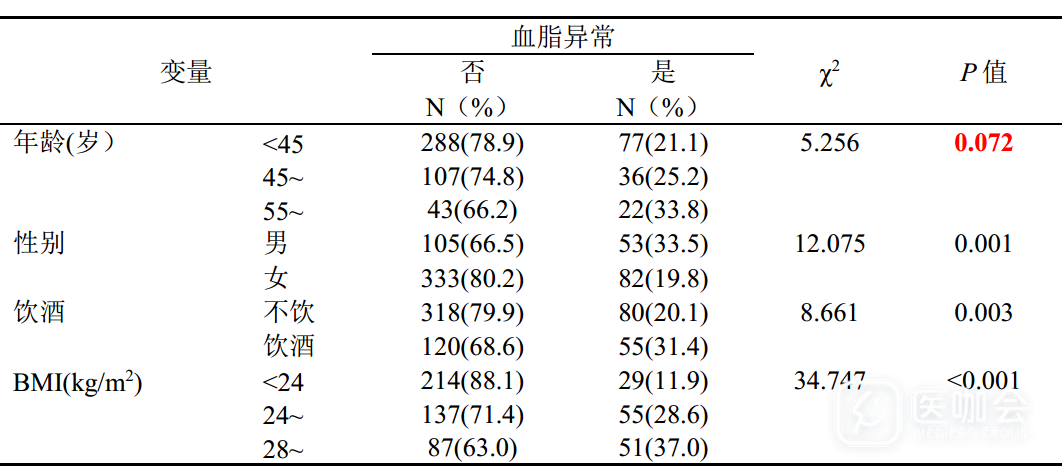
有的小伙伴会说,这不对呀,年龄是血脂异常的影响因素,地球人都知道啊,应该是哪里出了问题;也有的小伙伴可能会想,统计又不会骗人,没有统计学意义,就不应该算为影响因素……
先别着急将年龄从血脂异常候选影响因素中删去,我们再来看看多因素Logistic回归分析结果(表3)。SPSS软件的多因素Logistic回归结果显示,55-岁组血脂异常的患病风险是<45岁组的2.093倍。之所以会出现这种现象,是因为在做单因素分析时,往往无法识别混杂因素的存在,而混杂因素很可能会干扰我们关注的变量与结局之间的关系。













确认删除