




大致浏览后发现,主题词包含“随机 and(区组 or 分层)”的这1%的文献,大多数是因为主题词中有“随机分组”和“分层分析”而被检索到,而不是“分层随机化”。
可以猜想的是,中文报道的研究中,很少使用分层(区组)随机分组,或者使用了但未详细报道。
“只会简单随机化?Naive!”中已经介绍,简单随机分组时,组间人数不相等才是大概率事件。那么,为什么中文文献中,绝大部分采用简单随机分组,但两组样本量完全相等的研究报告那么多呢?
二、为什么要实施区组随机化
理想情况下,简单随机分组后,就能使1)组间基线特征基本均衡;2)组间人数基本相等; 3)组间重要协变量均衡。(重要协变量指的是与主要评价指标具有较强相关关系的预后因子,如年龄、疾病严重程度等。)然而,实际情况并不是这样的。相反,简单随机分组时,组间人数不相等才是大概率事件。
举例来看,某RCT纳入10名研究对象,如果简单随机分组为干预组(A)和对照组(B),就有8.8%的概率产生分配出以下样本量:干预组8名,对照组2名;或者干预组2名,对照组8名。两组人数完全相等的概率只有24.6%。另外,如果不同特征的研究对象入组时间明显不同(如早期进入研究的都病情较重),也会对试验结果产生影响。
区组随机化就能解决这个问题。
实际上,简单随机分组在临床试验中使用已经很少,而分层区组随机分组(Stratified Blocked Randomization)才是目前临床试验中应用最多最广泛的方法。
三、区组随机化如何实施
所谓区组 (Block),我们可以把它想象成一些格子(图3-1)。在分配研究对象时,先将研究对象装在这些格子中,再随机分配,并可以保证每个格子中的干预组(A)和对照组(B)的研究对象数量完全相等。 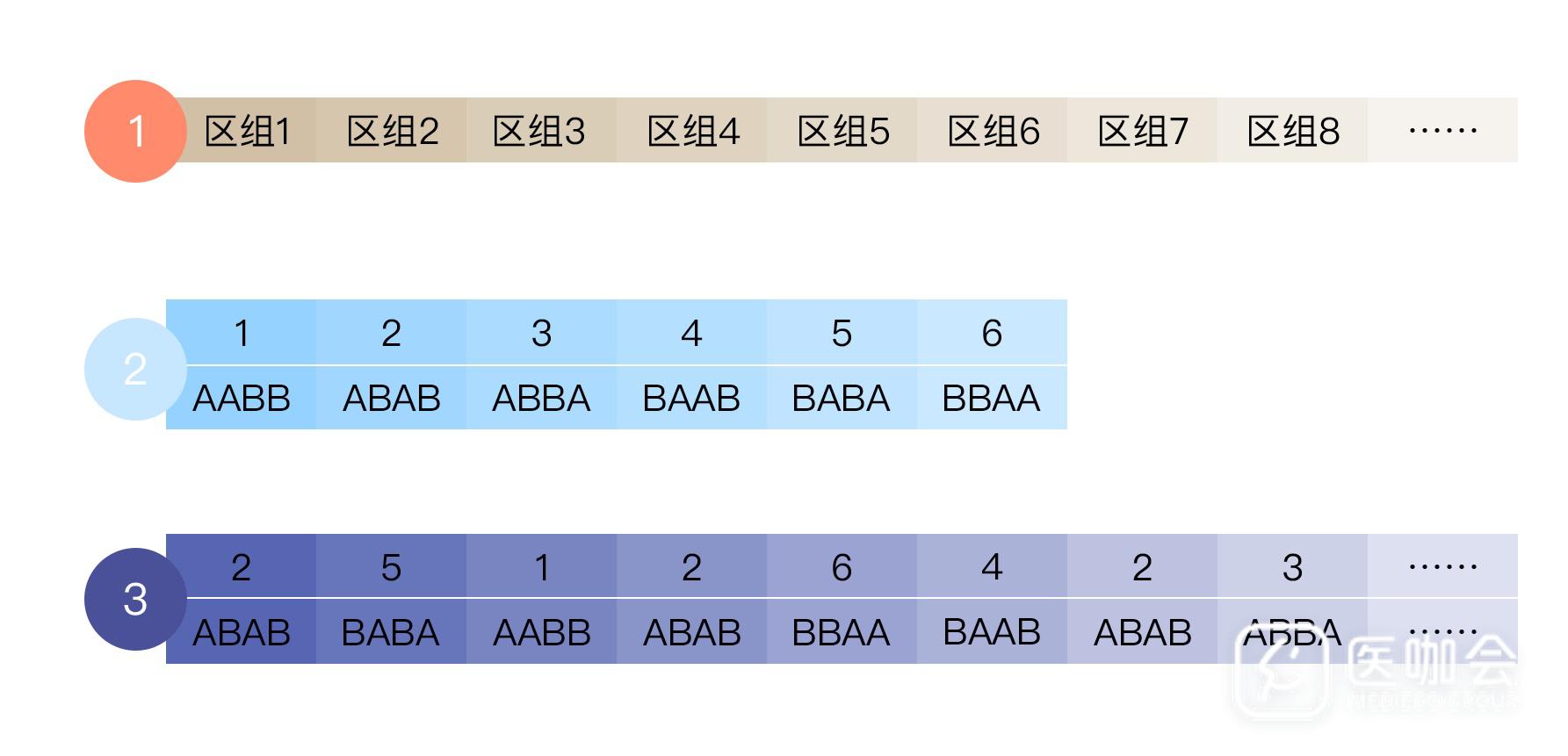










确认删除